Heartbeat Monitoring
Watch scheduled tasks, background daemons, server processes, and job queues with simple HTTP check‑ins and reliable on‑call alerting.
Heartbeat Monitoring:
Periodic heartbeats are the only reliable way to monitor distributed systems. All web systems are distributed systems. Heartbeat monitoring helps you catch failures before they impact users.
Most applications rely extensively on scheduled tasks, background daemons, server processes, and job queues to power their data pipelines, backups, emails, reporting, and more. When these systems break, they’re much less visible than a website outage, so they can sometimes fail silently for days or weeks before anyone notices.
Simple Check-Ins:
Your systems “check in” with a heartbeat by sending a simple HTTP POST request to our API. If the next check‑in is late, we create an incident, page the right people via loud critical alerts to our iOS and Android apps, post the incident to your Slack channel, and keep alerting and escalating until someone on your team acknowledges. Or, if it can wait, we can defer the alerts until your preferred business hours, to avoid waking you up at 3am.
TLDR:
Built for small engineering teams, HeyOnCall pairs heartbeat monitoring with on‑call alerting in one product for superior reliability and simplicity. Get impossible-to-ignore critical alerts that bypass Do Not Disturb, plus Slack, email, webhooks, and more. Defer important-but-not-urgent alerts until the morning so you don’t burn out your team with 3am wakeups. HeyOnCall is designed from the ground up to reduce false positive alerts (getting alerted when your system is actually fine) and false negatives (missing an outage due to broken monitoring or alerting).
Screenshots
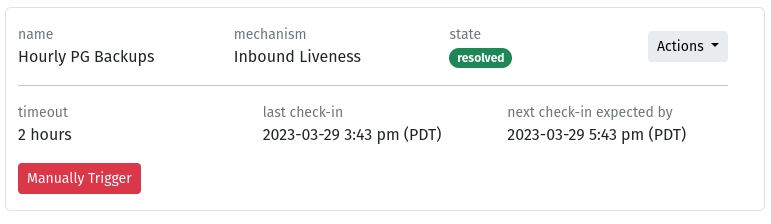

Heartbeat Monitoring: HeyOnCall vs. Alternatives
| Differentiator |
|
Alternatives: Roll Your Own | Alternatives: Enterprise | |
|---|---|---|---|---|
| Monitoring | Simple, flexible HTTP POST heartbeats. | Not typically a roll-your-own solution: it requires hosting a separate server (on different infrastructure) to receive the check-ins. | Varies, but similar. | |
| Business hours schedules | Defer important-but-not-urgent alerts (like a backup script failing) until your preferred weekdays and hours. | No differentiation between urgent and non-urgent alerts. Burns out your on-call team waking them up for things that can wait until the morning. | High complexity: requires multiple schedules, overrides, and routing rules. | |
| Alerting | iOS/Android “Critical Alerts” bypass Do Not Disturb and volume/mute settings. Repeat until acknowledged. Will wake you up! | No mobile app. No critical alerts. Emails or Slack alerts are easy to miss for hours. | Varies, but similar if configured correctly. | |
| On‑call | Integrated on-call rotation schedules and escalations. | No on-call schedules or escalations. You probably end up with a noisy Slack channel that everybody ignores. | Separate products for monitoring and on-call: requires integration glue between them, so there are more moving parts to fail during an outage. | |
| Silencing | Quick silence with selectable timeout at the trigger, service, or organization-wide level. Ensures you don’t keep getting alerts while you’re fixing the issue, and ensures you don’t inadvertently stay silenced forever. | Nope. Keep getting bombarded with alerts while fixing the issue. | Mute one monitor at a time. Forget to unmute after the incident is over, so you miss the next incident. | |
| False positives (noisy alerts) |
Customer-level: False positives are reduced to your preferences via customizable consecutive-failure thresholds / timeouts. Platform-level: False positives are reduced through continuous control group self-checks, extensively tested codebase, and code paths designed to differentiate our network incidents from yours. |
Tracking state history adds complexity and room for error. Can’t easily differentiate between failures of your monitoring system and failures of your application. |
Filter rules and thresholds are split between separate monitoring and on-call products. | |
| False negatives (missed alerts / blind spots) |
Customer-level: Missed alerts are reduced via: alerts repeat until acknowledged; configurable multiple delivery channels per user; configurable multi-level escalations. Platform-level: False negatives are reduced via extensive CI test suite, continuous production self‑checks, and external monitoring. |
Tends to be weakly tested, running on separate infrastructure (hopefully), ignored for months, and silently failure-prone. | Customer-specific glue (webhook integration) between separate monitoring product and on-call product fails silently (webhooks/auth headers/network issues), resulting in missed alerts right when you need them. | |
| Pricing | Simple, flat $/month pricing. Free tier forever. | In-house engineering time ($$$) to build and maintain. | Annoying $$/user/month or $$/monitor/month with big enterprise sales teams and long-term contracts. | |
Heartbeat Monitoring FAQ
Why do background daemons, server processes, and job queues need monitoring?
Anyone who has operated a production application for long enough will tell you that cron job schedulers break, fail with exceptions, run out of memory or storage, break when software dependencies change, and otherwise stop operating properly.
These systems run fine for weeks, months, or years without issues, then suddenly fail in ways that often go unnoticed for a while.
Heartbeat monitoring makes sure your critical systems perform as expected, and makes sure you’re the first to know when they don’t.
What’s a heartbeat?
In our case, a heartbeat is a simple HTTP POST request that your system sends to our API to indicate that it’s still alive and functioning properly.
More generally, a heartbeat is a signal from one system that says “I’m still alive and everything is ok!”, paired with a timer running on a monitoring system that says “If I don’t hear from you in X minutes, I’m going to assume you’re dead!”
Heartbeats go by many other names, such as:
- Check-in
- Health check
- Watchdog timer
- Liveness/readiness probe
- Dead man’s switch
How does your hosting company know their emergency generator will work for the next power outage? They don’t. They only know that it ran fine the last time they tested it. If they just tested it a week ago, the odds of it working are much better than if they last tested it 3 years ago.
The same is true of software systems. Doing checks (heartbeats) on a regular basis is the only way to know if a system is still alive and functioning properly.
What if my service is partially degraded, but still up?
Heartbeats can absolutely be used to detect partial degradation, but it’s up to you to define what “degraded” means for the context of your service.
For example, suppose you’re monitoring a job queue. You might have one scheduled job that sends a heartbeat every minute. This tells you that the job queue is still up, and that jobs are being processed.
But you may also want a metrics-driven heartbeat: for example, a scheduled job that only sends a heartbeat if the pending queue size is below a certain threshold. Or another that only sends a heartbeat if at least a certain number of jobs have been processed in the last X minutes.
Other platforms may call these “metrics-driven alerts”, but at the core, they’re really heartbeats: looking at whether some boolean condition is met or not within some X minute check interval / grace period!
What can go wrong that monitoring catches?
The big categories are resource exhaustion, misconfigurations, broken deploys, and infrastructure issues. More specific examples:
- Out of memory
- Disk full
- Network issues (DNS failures, TCP connection timeouts, TLS/SSL errors, etc.)
- External API issues (upstream API outages, API changes, billing issues, etc.)
- Server overload (too many requests, too much traffic at once)
- Unresponsive servers (process hangs, memory leaks, restart loops)
- Environment drift (missing or changed environment variables, secrets, or permissions)
- Breaking changes when upgrading software dependencies
- Hosting / PaaS provider incidents/outages
Who needs heartbeat monitoring?
- Imagine your job queue stops processing jobs.
- Imagine your server no longer has network connectivity.
- Imagine your background daemon ran out of disk space.
Would these issues affect your revenue or reputation? If so, you probably need heartbeat monitoring.
Who doesn’t need heartbeat monitoring?
If you’re okay with your systems failing silently for weeks, months, or years, you probably don’t need heartbeat monitoring.
When do I get alerted?
You choose how long of a timeout needs to pass without a heartbeat check-in before we alert. Your timeout should include the opportunity for retries and a grace window for runtime variation.
You probably don’t want to get woken up by a loud alert at 3am if your once-an-hour data ingest scheduled job is running slow and late to check-in by 5 minutes, but then successfully finishes a few minutes later. (It’ll already be resolved by the time you open your laptop.)
On the other hand, if your data ingest job is production-critical and has been down for a longer period (several chances to retry), you might want to get woken up and start debugging.
There are real tradeoffs in setting your timeout threshold, but we typically recommend setting a timeout that is long enough that the issue is unlikely to fix itself.
But I don’t want to get woken up at 3am!
Same here! :) Many issues are important to fix, but can realistically wait until the morning, or until Monday morning. We call these “important-but-not-urgent”.
That’s why we built Business Hours Schedules, which you can enable on a per-monitor basis, to defer any alerts until your preferred business hours. So you can fix the backup script at 10am, not 3am.
Who gets alerted?
Alerts route to the on‑call person in your on-call rotation schedule.
This works for teams-of-one too: until you add teammates, the default on-call schedule is just you, 24/7!
How do I get alerted?
Alerts are sent via the free HeyOnCall mobile apps for iOS and Android.
We have special permissions to deliver “Critical Alerts” on both iOS and Android. Critical alerts bypass the phone’s Do Not Disturb and silent/vibrate modes. They are LOUD and impossible to ignore.
The alerts will keep getting sent repeatedly (at a configurable interval) until you acknowledge the incident.
That sounds incredibly annoying! How do I turn it off?
Acknowledging the incident stops the alerts.
You can also configure non-critical alerts, which will be delivered as normal push notifications. These respect your phone’s normal Do Not Disturb and silent/vibrate modes.
We also have a vibrate-only mode, which will still buzz in your pocket, but won't make any sound.
During an incident, you can also silence all alerts at multiple levels up to organization-wide, so you don’t keep getting paged while you’re in the middle of trying to debug things.
What if I don’t notice the alert?
We have escalation rules built in. You can configure HeyOnCall to, for example, page the next person after 15 minutes, then page the team’s manager after 30 minutes, then page the CTO after 60 minutes. Any one of those people acknowledging the incident will stop the escalation.
Can I get alerts in Slack?
Yes. Connect Slack and our bot will post messages into your desired Slack channel for team visibility and collaboration. You can use this Slack channel for team awareness, while you rely on the iOS/Android critical mobile alerts for wake-you‑up-at-3am paging.
What makes HeyOnCall better than alternatives?
HeyOnCall helps you avoid burning out your engineering team by sharing the responsibility with an on-call rotation schedule, while deferring any important-but-not-urgent alerts until your regular business hours.
Alternative solutions often require you to stitch together separate monitoring and on-call alerting tools using brittle webhooks between them. For example: would you really trust your self-hosted monitoring script to be able to send a POST request to your third-party alerting service exactly when you’re in the middle of a flaky network outage? :facepalm: Not exactly a recipe for reliability. That's exactly why external heartbeat monitoring is so important!
HeyOnCall integrates heartbeat monitoring, website monitoring, on‑call schedules, and alert delivery in one product, which removes fragile links and makes the overall system more reliable.
Critical alerts. On-call schedules. Business hours schedules. Escalations. Monitoring for websites, APIs, cron jobs, and SSL certificates. All built-in and battle-tested. Designed for developers, by developers. Simple, flat pricing. Free tier forever.
How fast can I get started?
Sign up (free tier forever), create a trigger, and make a POST request in about a minute.